Generative AI, broadly speaking, are a group of algorithms and models that have the capability of generating new content that resembles, and in many cases is indistinguishable from, human-created content. This content can be images, music, videos, and of course, text.
Large Language Models (LLMs) are a specific type of generative AI model that are particularly focused on understanding and generating human language. These models have a wide range of applications, including chatbots, language translation, text generation, summarization, and more.
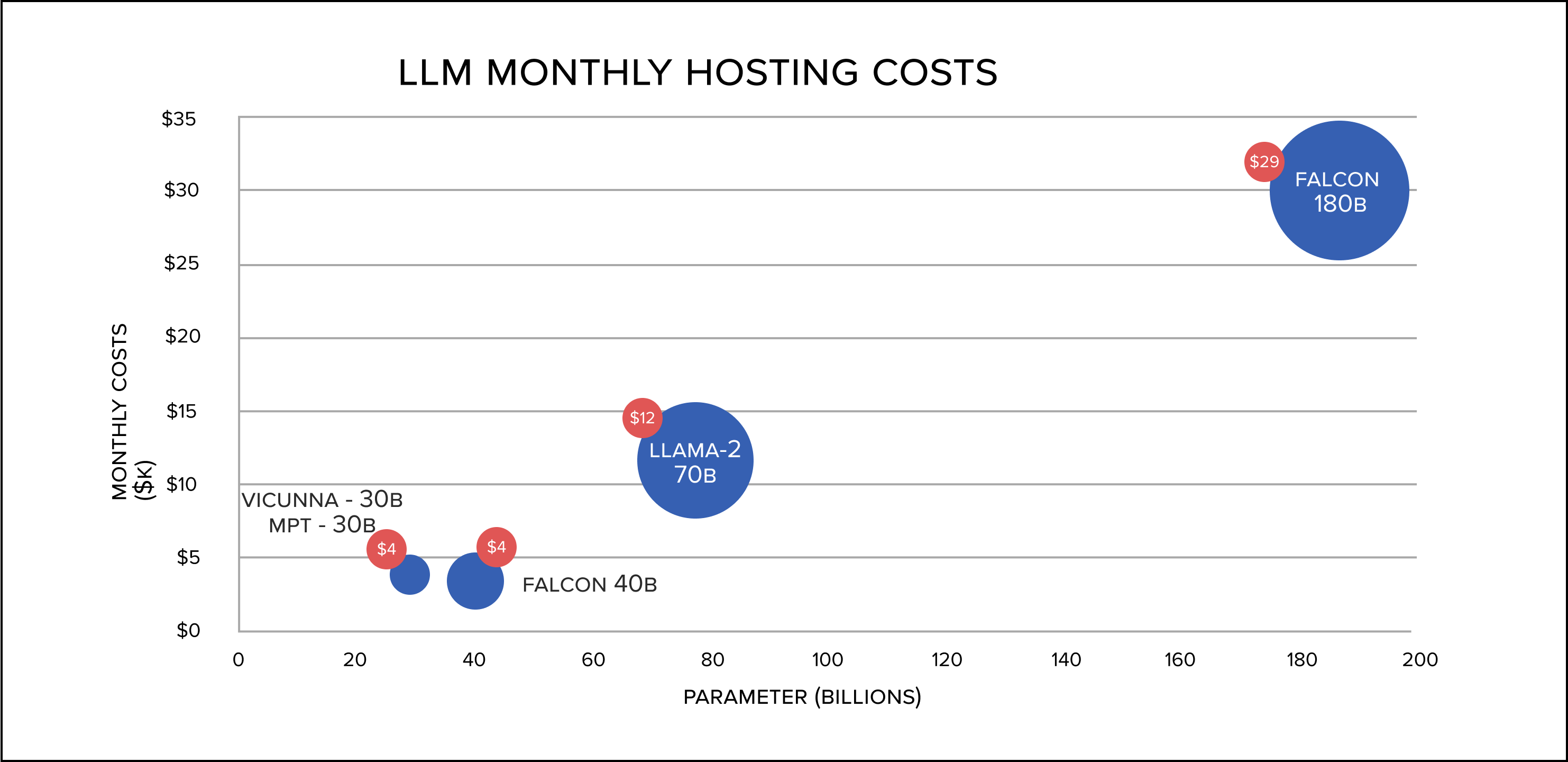
Examples of LLMs range from proprietary models, also referred to as paid models, such as OpenAI’s GPT, Google’s Bard, and Google Gemini, to open-source models, such as Meta’s LLaMa2, Falcon, Mistral, OPT, Mosaic, and Vicuna.
These models are a powerful advancement in Natural Language Processing (NLP) and are trained on vast amounts of text data, allowing them to generate coherent and contextually relevant text-based responses when prompted.
Let’s go through each key consideration – Performance, Model Dimensions, Usage Rights, and Cost – breaking down the advantages and limitations of Open-Source and Proprietary Models in the process.